
论文预览链接:https://www.researchgate.net/publication/371101297
代码链接:https://github.com/ECNU-Cross-Innovation-Lab/M3DFEL_replicate
作者:王晗阳、李博*、刘峰*、周爱民*等
单位:华东师范大学,腾讯优图实验室
摘要:动态面部表情识别(DFER)是一个快速发展的领域,主要识别视频格式数据中的面部表情。以前的研究将非目标帧视为噪声帧,但我们提出应将其作为一个弱监督问题来处理。我们还发现DFER中小范围和长范围时序关系的不平衡。因此,我们引入了多三维动态面部表情学习(M3DFEL)框架,该框架利用多实例学习(MIL)来处理不准确的标签。M3DFEL生成三维实例来模拟强大的小范围的时序关系,并利用3DCNNs进行特征提取。然后,动态长期实例聚合模块(DLIAM)被用来学习长期的时间关系,并动态聚合实例。关系,并动态地聚合实例。我们在DFEW和FERV39K数据集上的实验表明,即使使用最vanilla Restnet18作为backbone,M3DFEL的性能优于现有的最先进的方法胜过现有的方法。源代码可在https://github.com/ECNU-Cross-Innovation-Lab/M3DFEL_replicate下载
01简介
面部表情在交流中是必不可少的。[26,27,45]在对话中,通过他人的面部表情了解其情绪是至关重要的。因此,面部表情的自动识别是各个领域的重大挑战,如人机交互(HCI)[25,34]、心理健康诊断、驾驶员疲劳监测[24],以及元人类[6]。虽然在静态面部表情识别(SFER)方面已经取得了重大进展[23, 43, 44, 55],但人们对动态面部表情识别也越来越关注。
随着大规模野外数据集,如DFEW [11]和FERV39K[46]的出现,人们已经为DFER提出了几种方法[21, 22, 31, 47, 54]。以前的工作[31, 54] 只是简单地应用一般的视频理解方法来识别动态面部表情。[22] 观察到DFER含有大量的噪声帧,并提出了一个动态类标记和基于片段的过滤器来抑制这些帧的影响。Li等人[21]提出了一种强度感知损失(Intensity Aware Loss),以考虑DFER中大量的类内和类外损失,使网络对于最不确定的类别提供更多的注意力。然而,我们认为DEFR需要特殊的设计,而非被视作视频理解和SFER的结合。尽管这些工作[21, 22, 47]发现了DFER中的一些问题,他们的模型只是用了很粗糙的方式解决它们。
首先,这些工作没有认识到,DFER中非目标帧的存在实际上是由弱监督造成的。在收集大规模的视频数据集时,注释标签的精确位置是消耗大量人力的,而且具有挑战性。一个动态的面部表情可能包含非目标情绪和目标情绪之间的变化,如图1所示。如果没有一个可以指导模型的位置标签 忽略不相关的帧而将注意力放在目标上,模型很可能被不准确的标签所误导。因此,将这些非目标帧直接建模为噪声帧是肤浅的,而背后的弱监督问题 仍然没有得到解决。
第二,以前的工作直接跟随使用时间序列模型,而非针对DFER进行专门设计。然而,我们发现在DFER中存在小范围时序关系和大范围时序关系的不平衡。例如,一些微表情可能在一个很短的片段中出现,而一些面部运动可能干扰单个帧,如图一所示。与此形成对比的是,一个在视频开始的开心表情和视频结束的开心表情之间几乎没有时序关系。所以,对整个时序关系进行建模或者使用完全不包含时序关系的聚合方法对于DFER都不适用。取而代之的是,一个理想的方法应该学习对强的小范围时序关系和弱的长范围时序关系进行建模。
为了解决第一个问题,我们建议使用弱监督方法来训练DFER模型,而非将非目标帧当作噪声帧。特别的,我们提出将DFER当作多实例学习问题进行建模,其中每一个视频都被认为是一个包含一序列实例的包。在这个多实例学习的框架下,我们不考虑视频中的非目标帧,只关注目标情绪。然而,大部分多实例学习方法是不考虑时间的,这对于DFER并不适合。所以,一个专注于DFER的MIL框架是很必要的,以解决不平衡的小范围时序关系和长范围时序关系。
本文提出的M3DFEL被设计来用一种统一的方法解决不平衡的小范围时序关系和大范围时序关系,以及弱监督问题。它使用3D-Instance 和R3D18的结合,来加强小范围时序关系的学习。实例的特征被提取后,立即被喂到Dynamic Long-term Instance Aggregation Module (DLIAM)当中,它把特征聚合成包级别的表达。DLIAM被专门设计来捕捉实例之间长范围的时序关系。此外,Dynamic Multi-Instance Normalization (DMIN)被用来维持包级别和实例级别的时间一致性,通过进行动态归一化。
总体上,我们的贡献可以被概括为如下:
1. 我们提出了一个弱监督方法来对DFER作为一个多实例学习问题进行建模。我们认识到DFER中小范围时序关系和长范围时序关系的不平衡,这使得建模整个时序关系或者使用时间无关模型都是不合适的。
2. 我们使用了M3DFEL框架提供一个统一的解决方案,针对弱监督问题和DFER中不平衡的小范围时序关系和长范围时序关系的建模
3. 我们在DFEW和FERV39K上进行了广泛的实验,而我们的M3DFEL达到了state-of-art,即使只用了最vanilla R3D18作为backbone。我们还进行了可视化实验来分析M3DFEL的表现,发现了未解决的问题。

图1 野外的动态面部表情。在第一排图像中,被摄者主要表现为中性,但视频却被标注为快乐,而没有说明表达情绪的确切时刻。在第二行中,从几个人物的角度看,情绪是明显的,但其中任何一个都是有噪声的的,不清楚的。在第三行中,所有的帧看起来都是中性的,但仔细分析一下面部运动随时间的变化,就会发现嘴角上扬,表明是在微笑。
02相关工作
2.1动态面部表情识别(DFER)
随着DNNs在计算机视觉任务中的成功[3, 4, 15–20, 35–38, 50, 51, 56, 57],自动面部表情识别(FER)也通过深度学习得到了改善。DFER方法与SFER方法不同,因为它们除了考虑每张图像的空间特征外,还需要考虑时间信息。一些方法采用CNN来提取每一帧的空间特征,然后用RNN来分析时间关系[28, 52]。有人提出了3DCNs来为3D数据建模,并联合学习空间和时间特征。Fan等人[5]提出了一个混合网络,利用后期融合将循环神经网络(RNN)和三维卷积网络(C3D)结合起来。Lee等人[14]提出了一个场景感知的混合神经网络,该网络以一种新颖的方式结合了3DCNN、2DCNN和RNN。Lee等人[13]提出了CAER-Net,这是一个用于情境感知情感识别的深度网络,它以联合和提升的方式利用了人类面部表情和情境信息。
最近,基于变换器的网络在提取空间和时间信息方面得到了普及。例如,Zha等人[54]提出了一个动态面部表情识别变换器(Former-DFER),它由一个卷积空间变换器(CS-Former)和一个时间变换器(T-Former)组成。Ma等人[31]提出了空间-时间变换器(STT)来捕捉每一帧内的判别特征,并对各帧间的上下文关系进行建模。
动态-静态融合模块[21, 22]用于从静态特征和动态特征中获得更加稳健和具有鉴别力的空间特征,可以有效减少噪声帧对DFER任务的干扰。此外,Wang等人[47]提出了双路径多激励协作网络(DPCNet),从较少的关键帧中学习关键信息用于 从较少的关键帧中学习面部表情表现的关键信息。
上述方法将DFER作为一个一般的视频理解任务来处理,没有考虑到由于不精确的众包注释而导致的问题的弱监督性质。此外,他们忽略了DFER中不平衡的小范围和大范围时间关系的问题,而仅仅依赖于一个序列模型。相比之下,M3DFEL框架通过解决弱监督的问题,和对不平衡的小范围和长范围时间关系统一建模,从根本上解决了这些挑战。
2.2多实例学习(MIL)
MIL是一种旨在解决不精确标记问题的技术[8]。传统上,每个样本都被当作一个实例包,只有当所有的实例都是负面的时候,这个包才被标记为负面。否则,该包被认为是积极的。MIL通常用于有大量的只有一个标签的样本的情况。在这些情况下,方法必须准确识别和含有大量负面实例的数据集中的正面实例。
MIL已被应用于各个领域,如WSOD(弱监督物体检测)[9,39]、动作定位[30]和WSI(整个幻灯片图像)分类[49, 53]。虽然没有研究将野外DFER制定为MIL问题,但我们可以从WSOD方法中得到启发,这些方法也解决了基于视频任务的MIL问题。例如,Feng等人[7]提出了一个端到端的弱监督旋转不变量空中物体检测网络,以解决没有相应约束的物体旋转。同时,Tang等人[39]引入了一种新的在线实例分类器改进算法,将MIL和实例分类器改进程序整合到一个深度网络中。将MIL和实例分类器精炼程序整合到一个单一的深度网络中,并在仅有图像级监督的情况下对网络进行端到端的训练。只用图像级别的监督来训练网络。
在识别情绪方面,MIL的使用已被探索。Romeo等人[33]探讨了一些现有的基于MIL的SVM在使用生理信号检测情绪方面的应用。Chen等人[2]主要关注疼痛检测的行动单元编码,并在MIL中应用基于聚类的最大运算进行实例融合。Wu等人[48]在MIL中采用了可区分的OR操作以隐马尔科夫模型作为分类器,在实验室控制的DFER,使用面部地标作为输入特征。所有这些方法都使用手工的特征,并采用传统的机器学习MIL方法来完成他们的任务。此外,实验室控制的DFER样本更加明确,环境和面部表情的动态是固定的。固定的,而野外的样本则更加复杂和具有挑战性。他们应用MIL方法的方法是 不适用于我们在野外DFER的情况。
通过对DFER的高级假设和观察,我们通过融合MIL管道内的不平衡时间关系的建模,设计了我们的新型MIL框架。与使用现有的MIL方法来融合手工的特征不同,我们在特征提取过程中对强的小范围时间关系进行建模,并在实例融合过程中学习长范围时间关系。
03方法
3.1总览
MIL流水线主要包含4个步骤:实例生成、实例特征提取、实例聚合,以及分类。在DFER问题中,我们使用的M3DFEL遵循这一流水线,并且优化了3DCNN,来从生成的3D实例中提取特征,并且学习小范围的时序关系。DILIAM被用来读长范围时序关系进行建模,同时动态地将实例融进一个包。为了维持在包级别和实例级别时间一致性,DMIN被引入。被使用的M3DFEL框架的概览见图2
3.2提出的方法
3D实例生成: 通过裁切视频生成实例对于MIL任务是一个常用的方法,因为它们通常是基于帧的任务,例如弱监督物体检测或动作定位。然而,在DFER中,一些帧可能没有捕捉到典型的面部表情,当subject在说话的时候。虽然这些帧自身表现得不正常,它们实际上表现了面部运动的动势。此外,相较于其他的MIL任务,不同类别的面部动作区别是细微的,这表明即使是小的运动也能导致预测情绪和特征的变化。
我们使用的3D实例生成用一种简单但有效的方法解决了这个问题。给定一个包含![]() 帧图片的视频
帧图片的视频![]() ,我们将视频裁切成
,我们将视频裁切成![]() 维度上的
维度上的![]() 部分。然后,包就可以被定义为实例序列:
部分。然后,包就可以被定义为实例序列:![]() ;其中
;其中![]() 表示第
表示第![]() 个3D实例。这个设计使得特征提器其能够通过捕捉跨实例的面部运动动作,和subject对话时候的情绪对强的小范围时序关系进行建模。这对面部动作和情绪区别不显著的DFER至关重要,即使是微小的动作也能显著影响预测的表情。
个3D实例。这个设计使得特征提器其能够通过捕捉跨实例的面部运动动作,和subject对话时候的情绪对强的小范围时序关系进行建模。这对面部动作和情绪区别不显著的DFER至关重要,即使是微小的动作也能显著影响预测的表情。
实例特征提取 vanilla R3D18被用来提取包内每个实例![]() 的特征
的特征![]() 。R3D18模型提取压缩的帧表示,并结合每个实例的相邻帧的时间信息。这就形成了一个实例的特征表示包,表示为
。R3D18模型提取压缩的帧表示,并结合每个实例的相邻帧的时间信息。这就形成了一个实例的特征表示包,表示为![]() ,其中
,其中![]() 表示通道的数量。
表示通道的数量。
动态长期实例聚合: 如前文所述,在DFER中存在着长范围和小范围时间关系的不平衡。由于基于三维实例的MIL设置加强了小范围时间学习,因此提出了动态大范围实例聚合模块(DLIAM)来动态聚合实例,同时对大范围时间关系进行建模。第一步是使用BiLSTM来捕捉实例之间的大范围时间关系。
此后,为了动态聚合实例的表征,我们首次应用Multi-Head Self-Attention (MHSA)来学习实例间的关系,得到了注意力权重 ![]()
此外,我们发现,实例的识别结果相当不稳定,这违反了情感状态在短时间内,如几秒,相对稳定和连续的常识。为了解决这个问题,我们从文献[29]和动态多实例归一化(DMIN)方法中得到启发,并设计了一种动态多实例归一化方法,以保持包和实例两个层面的时间一致性。我们定义了一组正则化器![]() ,并动态地调整重要性权重,其中bn表示包级规范化器,in表示实例级规范化器。令
,并动态地调整重要性权重,其中bn表示包级规范化器,in表示实例级规范化器。令![]() 和
和![]() 分别是第n个实例第c个通道通过正则化前后的值,且正则化过程可被写作如下,
分别是第n个实例第c个通道通过正则化前后的值,且正则化过程可被写作如下,

其中![]() 和
和![]() 分别是通过正则化器k估计出的该实例特定通道上的均值和方差,
分别是通过正则化器k估计出的该实例特定通道上的均值和方差,![]() 是为了数值稳定加的一个小的数,可学习的仿生变换参数由γ和β表示。正则化器k的重要性权重由
是为了数值稳定加的一个小的数,可学习的仿生变换参数由γ和β表示。正则化器k的重要性权重由![]() 和
和![]() 表示,并且被动态调整。
表示,并且被动态调整。
两个正则化器之间的区别在于用于估计统计值的数值设置,包级别的正则化器沿着每个包的N个实例C个通道计算统计量,
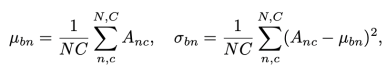
其中![]() ,表示单个包的值共享同一个包级别统计量。实例级别的正则化沿着N个维度计算统计量,
,表示单个包的值共享同一个包级别统计量。实例级别的正则化沿着N个维度计算统计量,
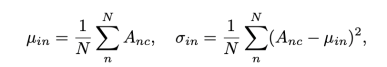
其中![]() ,表明实例级别的统计量在每个包的单个通道上是共享的。
,表明实例级别的统计量在每个包的单个通道上是共享的。
对于重要性权重,![]() 和
和![]() ,我们用softmax操作来保证
,我们用softmax操作来保证![]() ,且所有标量都被限制在0-1,
,且所有标量都被限制在0-1,
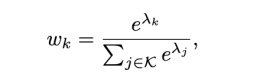
其中λ是可学习参数,用于调整不同归一化方法的权重。
对于实例的最终汇总,权重首先与经过一个sigmoid函数后的实例相乘。然后,利用Conv1D层将实例级特征X汇总为包级别特征![]() ,
,
![]()
然后包级别的特征被喂进全连接
层,以得到预测结果,交叉熵损失函数被用来监督结果。

图2 本文提出的M3DFEL框架的概述。(a) M3DFEL的流水线:三维实例生成、实例特征提取、长期实例聚合和分类。(b) 提出的DLIAM的结构。(c) 动态多实例规范化(DMIN)的简图。
04实验
4.1数据集
DFEW[11]是一个大规模野外数据集,于2020年被推出,包含超过16000条有动态面部表情的视频片段。这些片段是从全球1500多部电影中收集的,它们包含各种挑战性的干扰,如极端的光照、自我封闭和不可预测的姿势变化。每个视频片段都由10名训练有素的注释者在专业指导下进行单独注释,并被分配到七种基本表情中的一种,包括快乐、悲伤、神经质、愤怒、惊讶、厌恶和恐惧。我们采用DFEW提供的5个fold交叉验证设置,以确保不同方法之间的公平比较。
FERV39K[46]是目前最大的野外动态面部表情数据集,包含4个情景下收集的38935条视频片段,并被进一步细分为22个细粒度的场景。它是第一个具有大规模39K片段数量的DFER数据集,具有情景-场景划分和跨领域支持性。FERV39K中的每个视频片段都由30位专业标注者进行标注,以确保高质量的标签,并并标记为DFEW中的七个主要表情之一。我们使用FERV39K提供的训练集和测试集进行公平比较。
4.2实现细节
我们的整个框架是用PyTorch-GPU实现的,并在Tesla V100 GPU上进行训练。对于特征提取,我们采用了vanilla R3D18模型并利用Torchvision提供的预训练权重。这些模型使用AdamW优化器和余弦调度器训练了300个epoch,其中有20个warm-up epoch。学习率被设置为5e-4,最小学习率被设置为5e-6,权重衰减被设置为0.05。我们使用256的batch size,并应用0.1值的标签平滑。我们的数据增强方法包括随机裁剪、水平线翻转和0.4的颜色抖动。对于每个视频,我们总共提取16帧作为样本。在所有的实验中,我们使用加权平均召回率(WAR)和非加权平均召回率(UAR)作为评价指标,其中更强调WAR,因为它被认为是关键指标。
在接下来的实验中,我们主要使用DFEW[11]来进行进一步分析和讨论。
4.3与state-of-art方法的比较
我们将我们的方法与state-of-art的方法在DFER和FERV39K上进行比较。
DFEW 5个fold交叉验证后得到的结果如表1所示。可以观察到我们提出的M3DFEL在使用vanilla R3D18作为backbone的时候在WAR和WAR这两个指标上都达成了最好的表现。结果比使用NR-DFERNet [22]更好,在WAR指标有1.06%的差异,在UAR上有1.89%的差异。M3DFEL识别每一种表情的表现也见表1,更多详细分析见4.5
FERV39K 结果见表2. FERV39K是一个很有挑战性的数据集,导致得到的总体正确率比DFEW低。 M3DFEL分别超出NR-DFERNet [22]的WAR和UAR 1.70%和1.95%。值得注意的是,使用vanilla R3D18和LSTM,M3DFEL明显优于3DReSNeT18[10]和R18+LSTM[46],WAR分别高10.10%/9.27%,UAR分别高4.72%/5.02%,这证明了这一framework的有效性。
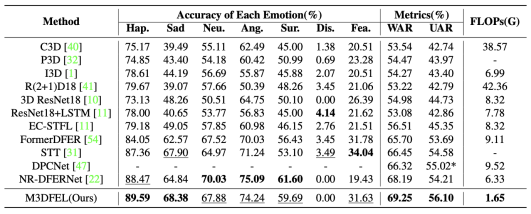
表1 我们的M3DFEL与state-of-art方法在DFEW上的比较(%)。*表示结果是根据论文中报告的混淆矩阵计算的。(黑体字:最好的结果,下划线:第二好)。
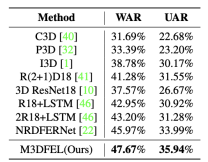
表2 我们的M3DFEL与与state-of-art方法在FERV39K上的比较(%)
4.4消融
不同包大小的评估 我们在DFEW上进行了消融实验来展示包大小的影响。当包的大小被设置为16,与被采样的帧数一致时,M3DFEL的设置退化为2D,此时ResNet18被用作backbone。将包大小设置为1表明整个被采样的视频都被一次性喂进了特征提取器,导致了一个普通的有监督学习范式,其中聚集模块不起作用。结果见图3.当M3DFEL设置随着包大小取16而退化成2D,模型达到了66.36%的WAR和53.56%的UAR。这个设置与其他设置相比有很大的差距,可能是因为DLIAM只学习了一个弱的时间关系,而缺乏对强的时间关系的建模。尽管学习强的时间关系是很重要的,但包大小为1的实验表明,它并不总是最好的解决方案。使用整个视频作为输入的WAR为68.04%,UAR为55.36%,落后于其他3DMIL设置。结果表明,在采样率为16的情况下,将包的大小设置为4,即每个实例包含4个帧,是一个可观的选择。
我们进行了额外的实验来分析单个实例的分类性能。如图3所示,当subject通过不明显的面部运动表达情绪的时候,基于3D实例的MIL模型可以捕捉到这些运动,并且做出准确的预测。与之形成对比的是,基于2D实例的MIL模型只能在几帧内成功。
对DLIAM的评估 我们进行了一个实验来研究提出的DLIAM在DFEW上的有效性,使用Average Pooling作为baseline方法。结果列于表4。比较结果显示,使用基于注意力的方法来聚集实例,就像现有的MIL方法那样,比基于BiLSTM的设置表现得更差。此外,结果表明,拟议的即插即用的DMIN以很小的成本提高了性能。完整的DLIAM设置(e)在DFEW上比基线要好1.02%/0.66%的WAR/UAR,充分表明DLIAM的有效性和DFER中长期时间关系建模的重要性。
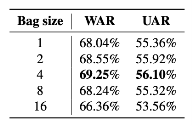
表3 不同包大小的消融研究。视频采样率为16。包尺寸1表示整个采样视频被送入特征提取器,使得MIL管道和实例聚合模块不适用。包大小为16表示每个实例由一个单帧组成。
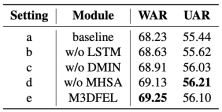
表4 使用的动态长期实例聚合模块的消融研究。DMIN是Dynamic Multi-Instance Normalization的缩写。MHSA是Multi-Head Self-Attention的缩写。
4.5可视化
为了进一步评估我们的方法的有效性,进行了可视化研究。
对不同MIL方法的可视化 为了调查M3DFEL如何起作用,我们得到了一个有强面部运动的实例的分类结果。如图4所示,基于二维实例的MIL在很大程度上受到主体说话时面部动作的影响。同时,一个简单的基于三维实例的MIL在第二个实例中捕捉到了被试者正在高兴地说话的信息,但它仍然将其他实例预测为其他非目标情绪。有了LDIAM,M3DFEL可以进一步认出具有迷惑性的表情,通过第二个实例提供的confidence,然后成功预测具有迷惑性的样本的情绪状态。
T-SNE可视化。我们利用t-SNE[42]来显示由我们的基线和M3DFEL提取的动态面部表情特征的分布。图5中的t-SNE图表明,基线所得到的特征缺乏辨别力,类别之间有很大的重叠。相比之下,我们提出的M3DFEL方法显示了类别之间更清晰的界限,有更集中的聚类。尽管如此,t-SNE图表明,中性表达的许多实例也存在于其他情绪中,而且其他一些情绪也可能被归类为中性。在DFER中,许多表达的强度比SFER低,注释者可能获得更多的信息,对这些微观表达更有信心。然而,识别这些低强度的表情对模型来说是一项具有挑战性的任务,导致难以区分中性和低强度的表情。
混淆矩阵。我们将我们提出的M3DFEL在DFEW Fold 1 5上评估的混淆矩阵可视化,以分析其结果。从图6中,我们观察到该模型在预测被标记为厌恶的视频的情绪时很困难。这是由于DFEW中严重的标签不平衡,其中Disgust视频的比例只有1.22%。因此,模型在训练过程中更有可能忽略带有Disgust标签的视频,导致在这种情绪上表现不佳。类似的情况也发生在恐惧标签上,它的比例为8.14%。该模型倾向于将一些带有 "恐惧 "标签的视频预测为其他情绪,这是因为缺乏足够的关于这种情绪的训练实例。此外,我们观察到,该模型倾向于更频繁地预测中性标签。这是因为将这些样本预测为任何其他情绪比预测为中性更容易错。
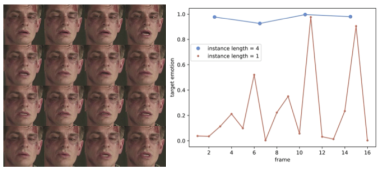
图3 基于2D实例和3D实例的MIL评估。目标表情为伤心。
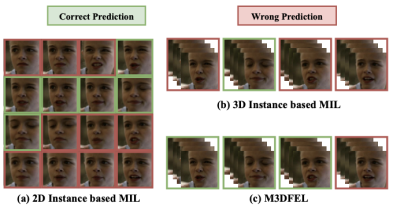
图4 不同MIL方法的可视化结果
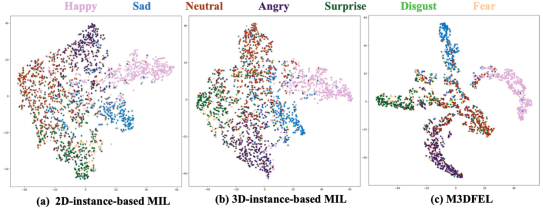
图5 通过不同的MIL方法获得的动态面部表情特征的二维t-SNE可视化[42],包括基于2D-实例的MIL,基于3D-实例的MIL和M3DFEL。这些特征是从DFEW数据集中提取的。

图6 我们提出的M3DFEL在DFEW Fold 1-5上评估的混淆矩阵。
05讨论
很明显,尽管提出了M3DFEL框架,DFER中仍有许多未解决的问题。我们对失败案例的分析表明,大多数失败案例发生在分类阶段,而不是MIL中的实例融合。例如,如果大多数视频帧是中性的,那么整个包的融合结果就是非中性的情绪,这是符合预期的。然而,该模型经常对非中性情绪进行错误分类,例如将 "恐惧 "分类为 "惊讶"。这表明目前的性能在很大程度上受限于模型的分类能力。
一个主要问题是不平衡的标签问题,由于数据集中缺乏具有这些标签的样本,厌恶和恐惧的准确率被牺牲了。这个问题在DFER中比在SFER中更严重,表明仅仅利用DFER数据集可能是不够的。这个问题可能的解决方案有改变学习或者自监督的预训练方法。另一个问题是,DFER中的一些表情比静态表情的强度低得多,这与微表情识别(MER)中的关键问题类似。利用光流等MER技术可能有助于解决这个问题。此外,一些先验知识,如landmark或面部动作单元,可以为模型提供有用的提示。除了这些问题,噪声标签问题、不确定性问题和硬样本问题都对DFER有很大影响。更重要的是,我们很难区分是应该强调还是削弱对样本的学习。除了现有的问题,我们希望模型不应该对数据集本身过拟合。由于FERV39K提供了跨领域的支持性,领域泛化是一个重要的研究方向。
06结论
在这项研究中,我们对DFER问题进行了深入分析,并提出了一个新的学习范式。我们利用了MIL的流水线,设计出M3DFEL框架,用一个统一的方法解决弱监督问题和不平衡的小范围与大范围时序关系问题。M3DFEL框架包括三维实例生成模块和动态长期实例聚合模块(DLIAM),前者用于学习强的小范围时间关系,后者用于模拟弱的大范围时间关系。该框架还实现了动态规范化,以保持包级和实例级的时间一致性。我们广泛的实验支持了我们对DFER问题的看法,并证明了提议的M3DFEL框架的有效性。此外,我们还确定了几个研究方向,可以指导这一领域的未来研究,如不平衡标签问题、不确定性问题等。
文献引用:Hanyang Wang, Bo Li, Shuang Wu, Siyuan Shen, Feng Liu, Shouhong Ding, Aimin Zhou.Rethinking the Learning Paradigm for Dynamic Facial Expression Recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 17958-17968.
主要作者介绍

王晗阳(第一作者)华东师范大学硕士。主要研究兴趣包括计算机视觉、可计算感知、情感计算。联系方式:faceeyes@126.com。

刘峰(共同通讯作者),华东师范大学博士。他是中国计算机学会高级会员,中国中文信息学会情感计算委员会委员,中国自动化学会区块链委员会创始委员,IEEE会员和中国心理学会会员。他的研究兴趣包括可计算感知、深度学习与区块链技术。联系方式:lsttoy@163.com。

周爱民(共同通讯作者),教授,博士生导师,分别于2001年和2003年在中国武汉大学获得计算机科学学士和硕士学位,并于2009年在英国科尔切斯特的埃塞克斯大学获得计算机科学博士学位。他是IEEE的高级会员。他已经撰写了80多篇同行评审的论文。他目前的研究兴趣包括进化计算和优化,机器学习,图像处理,及其应用。周博士是Swarm and Evolutionary Computation的副编辑和Complex and Intelligent Systems的编辑委员会成员。联系方式:amzhou@cs.ecnu.edu.cn。
注:其他作者Bo Li(共同通讯作者), Shuang Wu与Shouhong Ding为第一作者王晗阳在腾讯优图实验室的导师。
