
AffectGPT:提升可解释性多模态情感推理(下篇)
上篇链接:https://mp.weixin.qq.com/s/kcgk2ndYfBp8HOQNbAIebg
论文链接:https://arxiv.org/pdf/2306.15401.pdf
代码链接:https://github.com/zeroQiaoba/AffectGPT
论文作者:连政1、孙立才1、徐名宇1、孙海洋1、徐珂1、温卓凡1、陈顺1、刘斌1、陶建华2
单位:1中国科学院自动化研究所,2清华大学
引言:
多模态情感识别是人工智能领域的研究热点之一,其主要目标是整合多模态信息以识别人类的情感状态。当前工作通常假设基准数据集的情感标签是正确的,并关注于开发更有效的情感识别架构。然而,由于情感的主观性,不同的标注者可能会给同一个视频分配不同的标签。这种主观性很有可能导致现有数据集中存在标签模糊或者标注错误的问题,使得基于现有数据集开发的系统可靠性较低,难以满足实际应用需求。
针对上述问题,当前工作主要集中在增加标注者数量并使用多数投票来确定最相关或几个比较相关的情感标签。虽然这种方法提高了标注可靠性,但可能会忽略正确但非主导的情感标签,制约了现有模型描述微妙情感的能力。解决这个问题的关键在于提高标注结果的说服力,而不是简单的保留最相关或几个比较相关的情感标签。
在前期工作中,我们提出了一个名为“可解释性多模态情感推理(EMER)”的新任务。与以往主要关注情感预测的研究不同,EMER需要进一步解释这种预测行为背后的原因。推理过程的合理性将作为唯一的判别标准。本文进一步提出了基于EMER数据集的“音-视-文”对齐多模态大模型,AffectGPT。我们希望借助多模态大模型的多维理解与推理能力提升EMER任务上的性能。
数据集:
在该任务中,我们需要标注情感标签并提供标注依据。为了构建初始数据集,我们从大规模视频情感数据集MER2023中选择标注样本。由于标注成本较高,我们随机标注了100个带有非中性情感的样本,作为初始数据集。
我们招聘了六名标注人员。每个样本随机分配三名标注人员从以下四个方面标注情感以及情感依据:1)面部表情和身体动作;2)语气语调;3)文本内容;4)视频内容、环境等其他线索。然后,我们利用ChatGPT汇总多名标注人员的情感线索。最终,我们手动评估推理过程的合理性,并生成最终的情感描述。

图1:样例
评价指标:
针对EMER任务,我们提出了两种评测指标:基于ChatGPT的自动评价结果,以及人工评测结果。在自动评价指标中,我们分别对情感重叠度、情感线索重叠度、以及模态完备性进行评估。在人工评测中,我们聘请了5名标注人员对情感推理过程的合理性进行打分,分值1~4分别表示“完全错误”、“小部分正确”、“大部分正确”、以及“完全正确”。实验结果表明,自动评估结果与人工评测结果具有一定相似度,可作为情感理解能力的参考指标。
AffectGPT:
EMER任务需要综合理解多方面信息,我们借助了主流的多模态大模型框架Video-LLaMA。原始Video-LLaMA单独训练音频和视频分支,我们对模型进行修改,让其支持“音-视-文”三模态对齐数据。然后,我们将EMER数据集与VideoChat、MiniGPT-4、LLaVA的指令数据集结合,共同训练多模态大模型。
我们测试了6种多模态大模型在EMER任务上的性能。我们发现,现有模型在EMER任务上的结果较差。主要原因在于,现有多模态大模型主要关注于图像或视频场景信息描述,缺乏对人物主导的多模态信息进行理解与推理的能力。
由于自动评估结果与人工评测结果具有一定相似度,我们分别依赖于情感重叠度和情感线索重叠度,从六个基线系统中选择分值最高的预测结果,分别表示为“Baseline (Clue)”和“Baseline (Label)”。通过人工打分结果可以看出,模型集成策略有助于提升EMER性能。
此外,我们评价了AffectGPT在这个任务上的性能。相比于现有LLM,融合EMER数据集进行指令微调有助于提升情感理解能力。
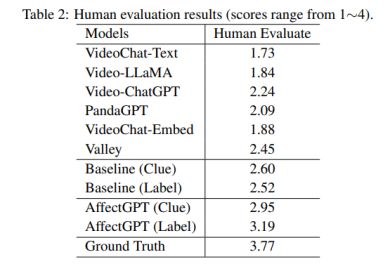
图2:人工评测结果
未来,我们希望建立更有效的模型去解决这个任务。同时,我们将降低标注成本以扩大数据集规模。
引用信息:
Zheng Lian, Licai Sun, Mingyu Xu, Haiyang Sun, Ke Xu, Zhuofan Wen, Shun Chen, Bin Liu, Jianhua Tao. “Explainable Multimodal Emotion Reasoning”. arXiv preprint arXiv:2306.15401 (2023).

连政,助理研究员,2021年于中科院自动化研究所模式识别与智能系统专业获得工学博士学位。2021年7月至今在中科院自动化所工作。研究方向为情感计算。

刘斌,副研究员,硕士生导师。2007年毕业于北京理工大学获得学士学位,2009年毕业于北京理工大学获得硕士学位,2015年于中科院自动化研究所模式识别与智能系统专业获得博士学位。2015年7月至今在中科院自动化所工作。研究方向为情感计算、音频处理等。

陶建华,清华大学长聘教授、博士生导师,国家杰出青年科学基金获得者,国家万人计划科技创新领军人才,享受国务院政府特殊津贴人员。完成多项国家和国际标准,论文和成果曾多次获国内外学术会议奖励。兼任中国计算机学会会士和常务理事、中国人工智能学会常务理事等职务。
