![]()

题目:HiCMAE: Hierarchical Contrastive Masked Autoencoder for self-supervised
Audio-Visual Emotion Recognition
期刊:Information Fusion
作者:孙立才1,2,连政2,刘斌1,2,陶建华3
单位:1中国科学院大学,2中科院自动化所,3清华大学
论文链接:https://authors.elsevier.com/a/1irJO_ZdCkVXqW
代码链接:https://github.com/sunlicai/HiCMAE
一、摘要
目前音视频情感识别的研究仍由传统的监督学习范式所主导。众所周知,监督学习范式十分依赖于人工标注的数据,只有在数据量丰富的条件下才能取得不错的性能。然而,由于情感固有的复杂性,音视频情感识别的研究长期面临着标注数据匮乏的问题,这给监督学习范式的进一步发展带来了巨大的挑战,也导致现有方法的性能提升已经遇到瓶颈。受近期自监督学习在众多领域大放异彩的启发,本文提出了一种自监督的音视频情感识别方法—层次化对比掩码自编码器(Hierarchical Contrastive Masked Autoencoder, HiCMAE)。HiCMAE旨在充分地利用海量无标注的且蕴含丰富情感信息的音视频数据来提升模型的性能,从而摆脱目前监督学习的困境并进一步推动音视频情感识别的发展。HiCMAE有机地结合了掩码数据建模和对比学习两种主流的自监督学习范式,并在此基础上提出了一种三管齐下的层次化表征学习策略(包括层次化跳跃连接、层次化跨模态对比学习以及层次化表征融合)来显式地引导模型中间层的学习从而提升整体音视频表征学习的质量。在包含离散和维度两种情感识别任务的9个数据集上的实验结果表明(如图1所示),HiCMAE以明显的优势超越了此前最优的音视频情感识别方法。
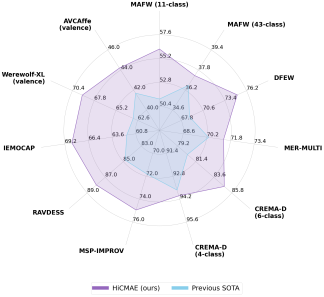
图1 HiCMAE与此前最优音视频情感识别方法在9个数据集上的性能对比
二、所提方法
HiCMAE的训练包括两个阶段,它首先在大规模未标注的且蕴含丰富情感信息的音视频数据上进行自监督预训练,然后在小体量的标注数据上进行微调。HiCMAE在预训练阶段采用和掩码自编码器(Masked Autoencoder, MAE)一样的非对称编码器-解码器架构,并且主要基于掩码音视频建模和对比学习实现自监督预训练。如图2所示,HiCAME首先对输入的音视频数据进行嵌入和掩码,然后分别通过音频、视频编码器以及跨模态融合编码器,接着通过音频、视频解码器重建出被掩码的音视频内容。考虑到音频和视频有着天然的配对性,HiCMAE 还引入了一个额外的预训练任务,即在音频和视频编码器输出的表征之间施加对比学习,来辅助自监督音视频表征的学习。
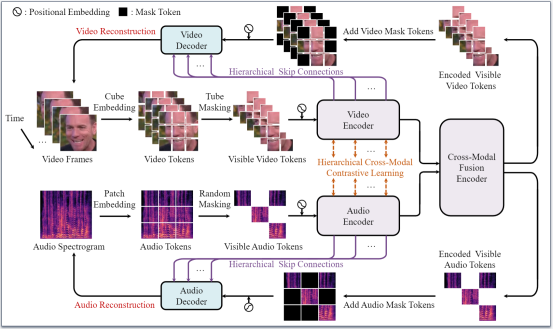
图2 HiCMAE的预训练示意图
最近几项关于掩码图像建模的研究表明,在训练的过程中对模型的中间层给予明确的引导可以促进模型学习到更好的表征。为此,HiCMAE 还设计了一种三管齐下的层次化表征学习策略来进一步提升音视频表征学习的质量。首先,如图2所示,借鉴计算机视觉中著名的图像分割模型 U-Net的架构设计,HiCMAE在音视频编码器和解码器的中间层引入了层次化跳跃连接,以促使编码器的中间层学习到更有用的特征表示并同时让解码器更好地完成掩码音视频重建的任务。其次,不同于传统的跨模态对比学习(比如 CLIP),HiCMAE 引入了层次化跨模态对比学习,即同时在音视频编码器多层(而非仅仅最后一层)的表征上施加对比学习,这样做的主要目的是逐步地减少异质音视频表征之间的差距并方便后续的跨模态表征融合。最后,考虑到编码器不同的层通常学习到不同类型的信息,HiCMAE 在模型微调时使用层次化表征融合来充分地整合编码器不同层级的音视频表征(详见论文),从而更好地服务于下游的音视频情感识别任务。
三、实验结果
(1) 模型版本和数据集介绍
为了满足真实应用场景中不同的需求,本文设计了三个版本的 HiCMAE,分别是基础版的 HiCMAE-B,小型版的 HiCMAE-S,以及微型版的 HiCMAE-T,三者的唯一区别在于表征维度的不同(详见论文)。
本文在VoxCeleb2上开展了HiCAME的自监督预训练。VoxCeleb2是一个很大的音视频数据集,其数据来自于著名视频分享网站 YouTube,主要是由对约 6000 位世界名人的采访视频组成,包含了超过一百万的视频片段。该数据集主要用于说话人识别领域的研究,虽然没有提供情感标签,但其中大量的采访片段蕴藏着不同人物真实且丰富的情感信息,而且提供了裁剪后的人脸视频,因此特别适合于音视频情感识别任务的自监督预训练。
本文在9个主流的音视频情感识别数据集上验证了所提方法的有效性,包括7个离散数据集(又细分为3个自然场景数据集:MAFW、DFEW和MER-MULTI,和4个实验室受控数据集:CREMA-D、MSP-IMPROV、RAVDESS和IEMOCAP)和2个维度数据集(Werewolf-XL和AVCAffe),这些数据集的主要统计参数以及具体的评估方式总结在表1中。
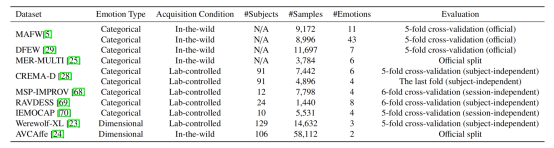
表1 本文使用的9个音视频情感识别数据集
(2) 性能对比
HiCMAE与此前最优的音视频情感识别方法在9个数据集上的总体性能对比展示在图1中,可以看出HiCAME有着显著的性能优势。为了进一步具体且深入地分析HiCAME的性能,本文展示了在MAFW和CREMA-D两个具有代表性的数据集上的对比结果,更多结果请参考论文。其中,MAFW包含两个子集,即MAFW(11类)和MAFW(43类),CREMA-D则包含CREMA-D(6类)和CREMA-D(4类)。
代表性数据集MAFW上的性能对比
首先,在 MAFW(11 类)子集上的性能对比如表2所示。可以看出,相较于最先进的音视频情感识别方法,所提方法取得了大幅的性能提升。具体来说,HiCMAE-B 在UAR和 WAR两个指标上分别以5.48% 和5.02%的优势超越了表现最佳的监督学习方法T-MEP。此外,最小的版本HiCMAE-T也在性能上大幅超越了T-MEP(+3.00% UAR和+2.26% WAR),并且参数量只有T-MEP 的三分之一左右,浮点运算量也减少了约 36%。更令人鼓舞的是,即便三模态的T-MEP(表2中的最底部)额外使用了对该数据集情感识别有很大帮助的文本信息(即人工标注的用于描述视频中人物情感行为的句子),它的性能仍然大幅落后于所提方法。还应该指出的是,T-MEP 依赖于其他领域强大的预训练模型(DeiT和 RoBERTa)对其单模态编码器的参数进行初始化,并且在不使用这些预训练模型时会出现明显的性能下降。因此,以上这些对比结果充分地表明了所提方法强大的表征学习能力,以及大规模自监督预训练相较于传统监督学习范式无与伦比的优越性。
除了总体的性能外,表2中也给出了每一类情感的准确率。可以看出,HiCMAE 在大多数类别上都取得了显著优于基线方法的性能,比如愤怒、厌恶、悲伤、蔑视和失望等。值得注意的是,在 MAFW(11 类)子集中,蔑视和失望这两类情感的样本仅占总数的 2.57% 和 1.98%。由于这种十分不平衡的情感类别分布,一些基线方法(如 T-ESFL等)完全无法正确地识别出这两类情感的样本,而所提方法将此前最佳结果分别提高了7.18%和8.14%。
此外,表2中还给出了单模态的对比结果。与最先进的单模态基线相比,所提方法仍然展现出强大的性能。具体来说,对于音频模态,所提方法取得了与三个主流的大型语音预训练模型(即wav2Vec 2.0、HuBERT和WavLM-Plus)相当或者更好的结果,同时所需的参数量和计算成本大大减少。比如,HiCMAE-T 的参数量仅为8M,浮点运算量仅为1G,而 HuBERT 的参数量为 95M,浮点运算量为 18G。在视觉模态上,所提方法也取得了十分不错的结果。例如,HiCMAE-B 超越了此前最先进的方法MAE-DFER,其UAR和WAR分别提高了0.48%和0.53%,并且模型大小只有MAE-DFER的38% 左右,浮点运算量也减少了约 36%。
最后,表3中展示了在 MAFW(43 类)子集上的对比结果。值得注意的是,由于该子集中不同复合情感类别的相似度较高(比如“愤怒+焦虑”、“愤怒+厌恶”以及“愤怒+焦虑+厌恶”)而且分布极度不平衡,因此该子集上的情感识别任务十分具有挑战性。对于音视频模态,与最先进的监督学习方法 T-MEP相比,所提方法在UAR和WAR两个指标上取得了具有竞争力或略微更好的性能。对于UAF和AUC两个指标,HiCMAE-B 相较于此前最佳的 T-ESFL有显著的性能提升。对于音频模态,所提方法取得了比三个大型语音预训练模型更好的性能。最后,在视觉模态上,所提方法也有和音频模态类似的性能提升。
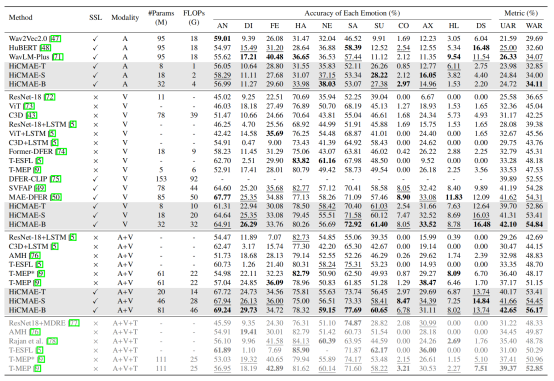
表2 在MAFW(11类)上的性能对比
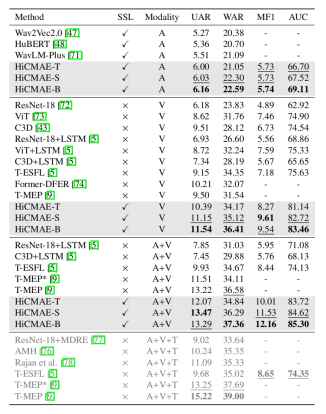
表3 在MAFW(43类)上的性能对比
代表性数据集CREMA-D上的性能对比
首先,表4中展示了在 CREMA-D(6 类)子集上的性能对比。对于音视频模态,与 MulT Base和 MulT Large两个自监督基线相比,所提方法有着显著的优势(+13% WAR)。值得注意的是,这两个基线也是在 VoxCeleb2 数据集上预训练的,但它们依赖于从其他模型中提取的特征,而不是直接使用原始数据作为输入。由于在特征提取过程中可能会丢失原始数据中的关键信息,因此这两个基线模型的性能有限。VQ-MAE-AV是另一个强大的自监督基线。与所提方法类似,它基于掩码数据建模并且也在VoxCeleb2 数据集上进行预训练,但缺点是需要两阶段的繁琐预训练流程。与VQ-MAE-AV 的两个版本相比,所提方法不仅表现出显著的性能提升,而且模型的预训练只需一个阶段即可完成。具体来说,相较于 VQ-MAE-AV 最好的结果,HiCMAE-T在WAR上提升了3.34%,同时参数量减少了约 33%。此外,进一步增加参数量后,HiCMAE-B 将性能差距扩大到更大到 4.49%,并在这个数据集上取得了最先进的结果。以上这些对比结果从侧面表明了HiCMAE中提出的用于促进层次化表征学习的策略的有效性。最后,所提方法也超过了最先进的监督基线。
在单模态设置下,所提方法仍然取得了具有竞争力的性能。例如,对于视觉模态,HiCMAE-B 虽略逊于最先进的方法 MAE-DFER(UAR和WAR的差距均小于 0.2%),但其所需的参数量降低了62% 且浮点运算量也降低了36%。对于音频模态,尽管 HiCMAE-B 在 UAR 和 WAR 两个指标上与性能最优方法 WavLM-Plus之间有着约 2% 的性能差距,但值得注意的是,WavLM-Plus 的参数量是 HiCMAE-B的3倍,而且浮点运算量是 HiCMAE-B的4.5倍,因此 HiCMAE-B的性能也是有竞争力的。
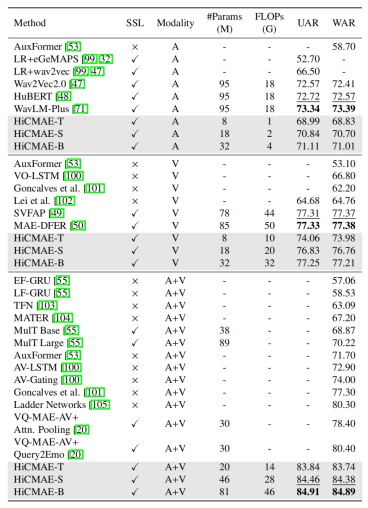
表4 在CREMA-D(6类)上的性能对比
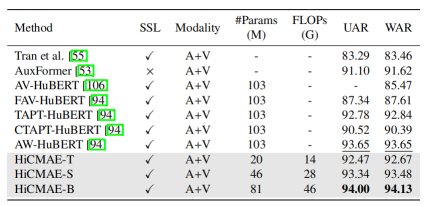
表5 在CREMA-D(4类)上的性能对比
除了这个数据集上默认的六类情感识别之外,本文还在一个包含四种情感的子集上进行了实验,其结果展示在表5中。这些对比基线大多属于自监督学习方法,比如 HuBERT 系列的模型。这些模型中除了 AV-HuBERT外(即 FAV-HuBERT、TAPT-HuBERT、CTAPT-HuBERT和 AW-HuBERT),均在 VoxCeleb2 数据集上进行预训练,而且使用显著更多的计算资源(32个Nvidia Tesla V100显卡)训练约10天的时间。与表现最佳的 AW-HuBERT 相比,HiCMAE-B 仍然取得了微弱的性能提升(+0.35% UAR和+0.48% WAR),并且HiCMAE 的参数量减小了约 21%,模型预训练的开销也显著降低(HiCMAE 只需要在4个 Nvidia Tesla V100 显卡上训练 5 天左右即可完成)。还应该指出的是,AW-HuBERT 还是一种半监督学习方法,它需要额外一个有标注的情感数据集和 VoxCeleb2 数据集的未标注样本进行情感信息的自适应,以获得相较于其他 HuBERT 模型更优的性能。因此,以上这些对比结果充分地表明了所提方法的优越性。
(3) 可视化结果
掩码音视频重建
图3中展示了 HiCMAE 在不同掩码率下的重建效果。图中的样例来自于从VoxCeleb2 的测试集(模型在预训练时从未见过)中随机选取的四位名人。对于每个例子,第一行展示了原始的语谱图和 8 帧的人脸图像,第二行和第三行展示了中等掩码水平(音频为 60%,视频为 75%)的输入以及相应的重建数据,最后两行展示了高掩码率的输入(音频为 80%,视频为 90%)及其相应的重建数据。从图中,可以看出,尽管相较于原始数据,重建后的数据丢失了一些细节信息,但语谱图和视频中重要的高层语义信息(比如语谱图中的谐波和视频中人物的微笑等)在中等和高掩码率下都能得到很好的恢复。这些令人满意的重建结果表明,HiCMAE 能够充分地利用十分有限的模态内和模态间的上下文信息来推断出大部分被掩码的音视频内容,这种在自监督预训练期间学习到的强大能力也为其在音视频情感识别任务上的优异性能奠定了坚实的基础。

图3 掩码音视频重建的可视化结果
情感表征空间
图4中展示了在 CREMA-D(6 类)数据集上利用 t-SNE对 HiCMAE学习到的情感表征空间进行可视化的结果。为了表明音视频融合的效果,图中同时展示了单模态和多模态的表征空间。其中,行表示不同的模态,列表示五折交叉验证。从图中可以发现,纯音频和纯视频的模型都学习到了比较好且具有区分性的情感表征空间。此外,多模态表征空间要比单模态表征空间更加紧致而且更具区分性,这一点可以从其更紧凑的类内分布和更分散的类间分布中看出。这一定性的结果也表明多模态融合可以充分地利用不同模态的互补信息从而显著提升情感识别的性能。

图4 情感表征空间的可视化结果
四、总结
总体来说,本文的主要贡献有以下三点:1)提出了一种新的自监督音视频情感表征学习框架 HiCMAE。作为将自监督学习引入音视频情感识别领域的早期尝试,HiCMAE 旨在充分地利用大规模无标注的且蕴含丰富情感信息的数据来学习更加泛化的音视频情感表征,从而摆脱目前监督学习方法的困境,并进一步推动音视频情感识别的发展。2)HiCMAE 有机地结合了掩码音视频建模和对比学习两种主流的自监督学习范式,并在此基础上提出了一种三管齐下的策略(包括层次化跳跃连接、层次化跨模态对比学习以及层次化表征融合)来促进层次化音视频表征的学习以提升整体表征学习的质量。3)在包含离散和维度两种音视频情感识别任务的9个数据集上的实验显示,HiCMAE以显著的优势击败了现有最先进的音视频情感识别方法,充分地表明了所提方法的优越性。
需要指出的是,由于算力资源有限,本文预训练的规模有限,未来的研究可以利用更大规模的无标注数据对更大尺寸的模型进行预训练通常可以进一步提升性能。此外本文的工作聚焦于视频和音频两个模态,下一步工作可以将更多的模态(比如文本和生理信号等)考虑进来。最后,HiCMAE在其他音视频任务(比如活跃说话人检测、深度伪造检测和说话面部生成等)上的表现也值得进一步探索。

孙立才,中国科学院自动化所和中国科学院大学计算机应用专业博士研究生。研究方向为情感计算,参与多项国家自然科学基金以及华为、蚂蚁金服等多项企业合作。

连政,助理研究员,2021年于中科院自动化研究所模式识别与智能系统专业获得工学博士学位。2021年7月至今在中科院自动化所模式识别国家重点实验室工作。研究方向为情感计算。参与多项国家自然科学基金以及华为、蚂蚁金服等多项企业合作。

刘斌,副研究员,硕士生导师。2007年毕业于北京理工大学获得学士学位,2009年毕业于北京理工大学获得硕士学位,2015年于中科院自动化研究所模式识别与智能系统专业获得博士学位。2015年7月至今在中科院自动化所模式识别国家重点实验室工作。研究方向为情感计算、音频处理等。


