
论文题目:基于阅读理解的论点对抽取
Have my arguments been replied to? Argument Pair Extraction as Machine Reading Comprehension
作者:鲍建竹,孙婧伊,祝清麟,徐睿峰
会议:Association for Computational Linguistics,2022
论文链接:https://aclanthology.org/2022.acl-short.4.pdf
论点对抽取任务
论点对抽取(Argument Pair Extraction, APE)[1]旨在从两篇相关的论辩文章中抽取论点对。一个论点可能包含一到多个句子,来自两篇文章的讨论同一问题的两个论点构成论点对。
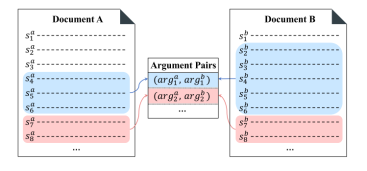
以往的用于论点对抽取的模型,将该问题建模为两个句子级别的子问题解决,首先通过序列标注判断每个句子是否属于一个论点,然后判断文章间所有论点中的句子关系,根据句子是否成对来推断论点是否成对[2]。这类方法忽视了论点级别的关联。因此,我们提出了一个两阶段的阅读理解(MRC)模型来解决APE问题,通过将论点作为查询来直接捕获论点与另一篇文章的交互关系,以实现论点级别的论点对抽取。我们在两个阶段中联合训练了一个MRC模型,以使两个阶段的训练能相互增益。我们设计的MRC模型主要包括两个模块,编码模块和跨度预测模块。
基于阅读理解的论点对抽取
编码模块
本文提出的方法可从两个方向进行,即,可以用文章A中的论点作为查询去寻找文章B中的配对论点,反之亦然。后文将以从文章A的角度寻找文章B中的配对论点的过程为例,介绍本文方法的两阶段的详细流程。由于要处理的文章很长,我们采用Longformer[3]作为基编码器。
在第一阶段中,我们构造AM查询来识别文章A中的所有论点。具体而言,我们将特殊符号“[AM]”与文章A中的token拼接输入Longformer,获得文章A中的token的向量表示,用于文章A中的论点挖掘。在第二阶段中,我们将文章A中的所有被抽取出论点分别作为APE查询,与文章B中的token拼接输入Longformer,获得文章B中所有token的表示,用于寻找文章B中与这些论点匹配的论点。
对于每次Longformer的输入,我们都对查询部分施加全局注意力,以更好地捕捉查询部分与目标文章间的联系。我们通过平均池化获得句子向量,并将一篇文章中得到的所有句子向量输入LSTM捕捉其间的长距离依赖,获得最后的句子表示。
跨度预测模块
对于每阶段阅读理解模型的输入,都可能抽取一到多个句子作为答案跨度。其中,第一阶段阅读理解抽取到的是一篇文章中所有可能的论点,第二阶段阅读理解抽取的是另一篇文章中与目标论点成对的论点。
受[4]启发,我们分别使用两个二分类器来预测论点在文章中所有可能的开始句位置和结束句位置。然后使用一个跨度分类器来判断任一对开始位置和结束位置是否能组成一个答案论点跨度。
训练过程
我们使用了三个交叉熵损失函数作为训练目标,包括开始损失、结束损失和跨度匹配损失。最后的损失函数是三个部分的加和。此外,我们使用同一个MRC模型在AM阶段和APE阶段联合训练。
实验与分析
主实验结果
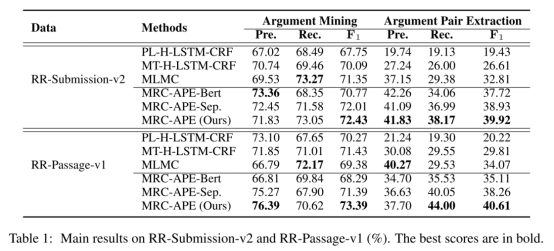
主实验结果如表1所示。对于AM 任务和APE任务,我们的MRC-APE模型在两个版本的 Rreview Rebuttal数据集上都取得了最佳性能。此外,在没有使用 Longformer 作为基础编码器的情况下,MRC-APE-Bert 在 APE 任务中取得了优于当前最优模型MLMC[2]的F1分数,表明我们模型的性能提升不仅仅是 Longformer 带来的。此外,在AM和 APE 任务上我们的MRC-APE模型 比 MRC-APE-Sep 模型取得了更好的结果,表明在两个阶段联合训练单个MRC模型,可以使模型在两个阶段的表现相互增益。
消融实验结果
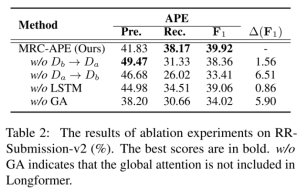
消融研究结果如表 2 所示。可以看出,使用两个方向的抽取,即从文章A的角度挖掘匹配论点对和从文章B 的角度抽取论点对,对我们的方法有很大贡献。其中使用文章A中识别的论点来提取文章B中的匹配论点在 RR 数据集中更为关键,删除这一过程会导致 APE任务的F1分数大幅下降。此外,在没有全局注意力的情况下,模型性能也会降低,因为它可以更好的交互查询论点和另一篇章之间的信息,从而可以学习更好的针对于该论点的表示。
总结
在本文中,我们提出将论点对提取(APE)任务建模为机器阅读理解(MRC)任务。 MRC 框架分别在两个阶段使用两种类型的查询,包括论点挖掘 (AM) 查询和论点对提取 (APE) 查询,来解决 APE问题。我们提出的方法可以更好地模拟论点级别的交互来进行篇章间的论点对抽取。在大型基准数据集上的实验结果表明,我们提出的方法实现了目前最优的性能。
引用
[1] Liying Cheng, Lidong Bing, Qian Yu, Wei Lu, and Luo Si. 2020. APE: argument pair extraction from peer review and rebuttal via multi-task learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 7000– 7011. Association for Computational Linguistics.
[2] Liying Cheng, Tianyu Wu, Lidong Bing, and Luo Si. 2021. Argument pair extraction via attention-guided multi-layer multi-cross encoding. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pages 6341–6353. Association for Computational Linguistics.
[3] Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. CoRR, abs/2004.05150.
[4] Leilei Gan, Yuxian Meng, Kun Kuang, Xiaofei Sun, Chun Fan, Fei Wu, and Jiwei Li. 2021. Dependency parsing as mrc-based span-span prediction. CoRR, abs/2105.07654.
上一篇:深度阅读丨跨语言情感分析研究综述
