针对基于知识对话任务的合成数据生成框架
论文信息:
Jianzhu Bao, Rui Wang, Yasheng Wang, Aixin Sun, Yitong Li, Fei Mi, and Ruifeng Xu*. A Synthetic Data Generation Framework for Grounded Dialogues. Proceedings of ACL 2023, 10866–10882.
论文链接:https://aclanthology.org/2023.acl-long.608v2.pdf
引言
训练基于知识的对话生成模型需要大量的基于知识的对话数据。然而,这类对话数据并不容易获得。因此,本文针对基于知识的对话任务,提出了一个合成数据生成框架SynDG,以生成大量的合成对话数据作为新的训练数据。利用预训练模型和无标注的知识数据(如维基百科文档,用户个性信息等),SynDG能够考虑对话流和整体对话的一致性。具体来说,给定无标注的知识数据,SynDG首先使用启发式的方法确定对话流,本质上是一系列的知识片段。然后,利用T5来逐步地将对话流转化为对话。此外,本文还设计了一个两级筛选策略来确保对话流和合成对话的一致性。在两个公开数据集上的结果显示,不管是在全数据和低资源的场景下,SynDG所生成的合成对话数据都能够显著增强基线模型的性能。
本文的贡献主要有以下几点:
1. 针对基于知识的对话提出一个合成数据生成框架SynDG,能够为基于知识的对话模型提供额外的训练数据。
2. SynDG能够模拟基于知识的对话中的对话流,并且能够同时在对话流和对话层面保证合理性。
3. 在两个公开数据集上的结果表明了SynDG所生成的合成对话数据对于基线模型是有很大帮助的。
给定一组基于知识的对话训练数据![]() ,其中
,其中![]() 是对话历史,
是对话历史,![]() 是包含许多知识片段的知识语料,
是包含许多知识片段的知识语料,![]() 是需要生成的回复。基于知识的对话任务的目标是从
是需要生成的回复。基于知识的对话任务的目标是从![]() 中训练出一个生成模型
中训练出一个生成模型![]() 。此外,本文用
。此外,本文用![]() 来表示对话中所有的utterance。
来表示对话中所有的utterance。
本任务的目标是使用一个合成数据生成框架来自动生成合成的基于知识的对话数据![]() 。然后,生成模型
。然后,生成模型![]() 能够更好的由
能够更好的由![]() 来训练得到。
来训练得到。
如下图所示,SynDG的框架主要由三个部分组成。在生成每个合成对话时,SynDG首先通过启发式的采样策略从非结构化知识数据中构建一个对话流。然后,通过微调后的T5模型将对话流中的每个知识片断逐步实现为一个utterance,产生一个合成对话。而后,SynDG用两个基于T5的评分器对合成对话在对话流级别和utterance级别分别进行评分。最后,SynDG根据分数过滤掉低质量的合成对话,得到最终的合成对话集。
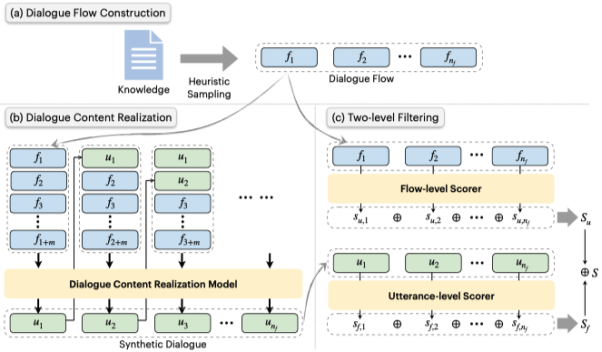
2.1. 对话流构造
本文将一个基于知识的对话中的对话流定义为一个知识片段的序列![]() ,其中
,其中![]() 是
是![]() 的长度,
的长度,![]() 可以是一个或多个知识片段,也可以是一个特殊的“[none]”符号,表示没有知识。此处,让每个
可以是一个或多个知识片段,也可以是一个特殊的“[none]”符号,表示没有知识。此处,让每个![]() 对应一个utterance,这样
对应一个utterance,这样![]() 同样表示对话中的utterance数量。此外,本文中默认对话中的两个参与者轮流发言,这样,
同样表示对话中的utterance数量。此外,本文中默认对话中的两个参与者轮流发言,这样,![]() 来自于一个参与者,
来自于一个参与者,![]() 则来自于另一个参与者。对于原始训练集
则来自于另一个参与者。对于原始训练集![]() 中的每个对话,可以很容易的获取其对应的对话流
中的每个对话,可以很容易的获取其对应的对话流![]() ,因为每个utterance所对应的知识片段是给定的。
,因为每个utterance所对应的知识片段是给定的。
本文根据原始训练数据中的对话流模式设计启发式采样方法,用于确定合成对话的对话流![]() 。本文在两个数据集上进行实验,一个是persona-grounded对话数据集PersonaChat,另一个为基于知识的对话数据集Wizard of Wikipedia (WoW)。对于PersonaChat,首先从训练集中随机抽取persona句子作为知识语料库
。本文在两个数据集上进行实验,一个是persona-grounded对话数据集PersonaChat,另一个为基于知识的对话数据集Wizard of Wikipedia (WoW)。对于PersonaChat,首先从训练集中随机抽取persona句子作为知识语料库![]() ,每个persona句子被视为一个知识片断。然后,根据启发式约束,从知识语料库中为每个回合抽取零个、一个或多个角色句子,从而形成一个对话流程。对于Wizard of Wikipedia,本文使用所选择的主题段落和第一个回合中的检索段落作为知识库
,每个persona句子被视为一个知识片断。然后,根据启发式约束,从知识语料库中为每个回合抽取零个、一个或多个角色句子,从而形成一个对话流程。对于Wizard of Wikipedia,本文使用所选择的主题段落和第一个回合中的检索段落作为知识库![]() 。然后,在合成对话的每个回合中,根据启发式的约束,最多从知识库
。然后,在合成对话的每个回合中,根据启发式的约束,最多从知识库![]() 中抽出一个知识片段。
中抽出一个知识片段。
2.2. 对话内容实现
在获得合成对话流之后,本文下一步训练一个对话内容实现模型,将对话流中的每一个知识片段一步步实现为一个utterance。通过这种方式,合成对话流被逐步转化为合成对话。此处是通过对话重建任务来微调一个序列到序列的预训练模型T5,作为对话内容实现模型。微调数据是由![]() 构建的。在微调过程中,
构建的。在微调过程中,![]() 中的每个utterance被视为目标序列,而其之前的对话历史和后续的对话流则被合并作为源序列。具体来说,对于第
中的每个utterance被视为目标序列,而其之前的对话历史和后续的对话流则被合并作为源序列。具体来说,对于第![]() 个utterance
个utterance ![]() ,目标序列就是其本身,源序列则为:
,目标序列就是其本身,源序列则为:
![]()
其中,![]() 表示对话历史中的utterance,
表示对话历史中的utterance,![]() 和
和![]() 表明要生成的目标序列应该主要基于知识片段
表明要生成的目标序列应该主要基于知识片段![]() ,
,![]() 是
是![]() 中的后续所有知识片段的数量。
中的后续所有知识片段的数量。
之后,使用微调好的这个T5模型便可以逐步地将![]() 实现为一段合成对话
实现为一段合成对话![]() 。进一步,将每个回复utterance
。进一步,将每个回复utterance ![]() 视为一个回复
视为一个回复![]() ,便能够得到一个合成对话的集合
,便能够得到一个合成对话的集合![]() ,这里
,这里![]() 是构造对话流时所使用的知识库。
是构造对话流时所使用的知识库。
2.3. 两阶段过滤
为了进一步提高合成对话的质量,本文进一步设计了一个两级过滤策略。它在对话流层面和utterance层面对合成对话进行评分,以剔除低质量的对话。具体来说,通过文本填充任务训练两个基于T5的模型,分别对对话流![]() 和合成对话
和合成对话![]() 进行评分。
进行评分。
训练数据同样是由![]() 构建的。在utterance层面,首先依次mask对话
构建的。在utterance层面,首先依次mask对话![]() 中的每个utterance,然后微调一个T5模型作为utterance级评分器
中的每个utterance,然后微调一个T5模型作为utterance级评分器![]() 来预测被mask的utterance。形式上,对于
来预测被mask的utterance。形式上,对于![]() 中的第
中的第![]() 个话语
个话语![]() ,对其进行mask,以获得源序列
,对其进行mask,以获得源序列![]() :
:
![]()
相应地,要预测的目标序列为![]() 。
。
在预测阶段,![]() 的utterance级别的分数由这样计算得到:
的utterance级别的分数由这样计算得到:
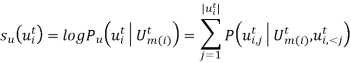
用这种方法,对于每个合成对话![]() ,可以通过mask每个utterance来获取
,可以通过mask每个utterance来获取![]() 个分数。之后,将这些分数取平均来作为总体的utterance级别分数
个分数。之后,将这些分数取平均来作为总体的utterance级别分数![]() 。
。
相似的,本文还微调另一个T5模型作为对话流级别的评分器![]() ,具体就是将上述的
,具体就是将上述的![]() 替换为
替换为![]() 作为训练数据。然后将该微调后的模型应用在
作为训练数据。然后将该微调后的模型应用在![]() 上来获取对话流级别的分数
上来获取对话流级别的分数![]() 。最终,
。最终,![]() 和
和![]() 的加和会被作为最终的总分数。
的加和会被作为最终的总分数。
本文在两个公开的基于知识的对话基准上进行了实验: Wizard of Wikipedia (WoW) 和 PersonaChat。
下面介绍本文所对比的基线模型。对于WoW,本文在两种设置下进行实验,即知识可见(KA)和知识不可见(KU)设置。前者在给定的知识下生成回复,而后者则需要先进行知识选择。在WoW上,本文对比的模型如下:
BB: 对于上述两种设置,使用BlenderBot(BB)作为回复生成模型,并将对话历史与真实的或者是预测的知识拼接起来作为输入。对于KU设置下的知识选择模型,这里对RoBERTa进行二分类的微调,以对知识片段进行排序和预测。其输入是对话历史和每个候选知识片段的拼接。
BB-SynDG: 使用SynDG框架产生的合成对话作为训练BB的额外训练数据。
对于PersonaChat,本文对比如下基线模型:
GPT2: 通过拼接persona和对话历史作为输入序列来微调GPT2。
GPT2-BT: Cao等人通过回译对训练对话数据进行增强,然后用增强后的数据和原始数据对GPT2进行微调。
GPT2-D3:改工作是为PersonaChat所设计的数据增强方法,它结合了多种技术和模型,如BERT、GPT2、反向翻译等。
GPT2-SynDG :用SynDG的合成对话取代GPT2-D3中的增强对话。
对于基于SynDG框架的模型(BB-SynDG和GPT2-SynDG),本文通过去除对话流级过滤(w/o FF)、utterance级过滤(w/o UF)或两者(w/o FF&UF),进一步进行消融实验。此外,本文还报告了在确定对话流时使用随机采样(BB-RS和GPT2-RS)而不是启发式采样的结果。
此外,实验中还通过只使用原始训练数据的1/16和1/32来证明SynDG在低资源情况下的能力。
3.2. 评价指标
自动评价:对于自动评估,本文采用了广泛使用的BLEU-4(B-4)、ROUGE-L(R-L)和Perplexity。此外,对于WoW,还使用F1得分来衡量生成的回复和真实回复之间的unigram重叠(F1),以及生成的回复和真实的知识之间的unigram重叠(KF1)。同时,在KU设置下的知识选择性能由准确度(ACC)来衡量。
人工评价:为了进行更全面的分析,本文进行了包含两个方面的人类评价。(1) Human likeness: 它衡量回复的流畅性、连贯性和参与度,即它是否类似于人类的回复。(2) Informativeness: 对于WoW来说,它评价一个回答是否包含适当的、正确的和事实性的知识信息。对于PersonaChat来说,它衡量一个反应是否与至少一个persona的句子一致。人类评价是通过成对比较的方式来得到的。
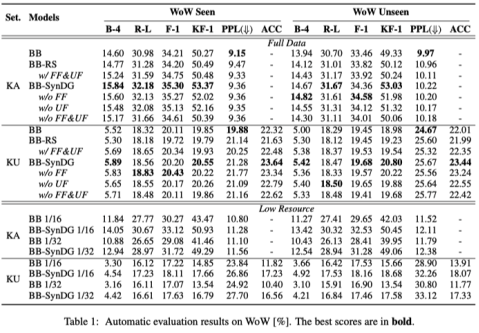
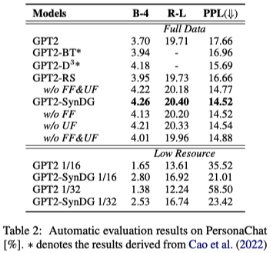
3.3. 自动评价结果
在两个数据集上的自动评价结果如下两个表所示。可以看到,不管是在知识可见还是只是不可见的情况下,加入合成数据作为额外的训练数据都能够提升基线模型的性能。而这种提升在低资源场景下更加明显。此外,消融实验的结果也表明了本文提出的两级过滤策略的有效性。
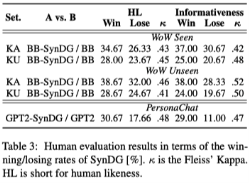
3.4. 人工评价结果
人工评价的结果如下表所示。结果表明,SynDG的引入给基础模型(BB和GPT2)带来了明显的改善,可以生成更自然、更有知识的反应。在WoW上,SynDG在KA设置下的优势比在KU设置下更明显,这与自动指标的结果一致。
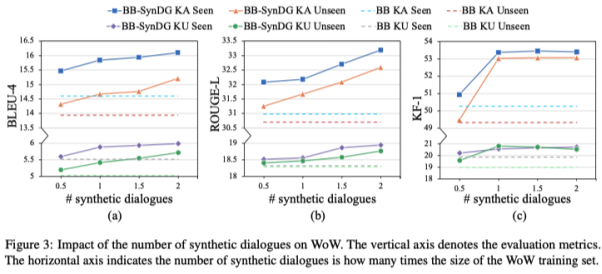
3.5. 合成对话的数量的影响
通过SynDG,可以自动生成许多合成对话。然而,选择多少个合成对话作为额外的训练样本是最合适的?为了回答这个问题,本文在下图中展示了不同数量的合成对话对WoW上的模型性能的影响。
从图(a)和(b)中,可以观察到,随着合成对话数量的增加,BLEU-4和ROUGE-L的分数趋于增加,显示了SynDG框架的潜力。然而,通过图(c),可以发现KF-1得分在快速增加后趋于稳定。这可能是由于本文所使用的语言模型的规模限制了合成对话的质量上限。另外,还可以发现,增加合成数据的数量可能不会无限制地提高性能。当合成数据量达到原始数据量的两倍时,所带来的改善就不明显了。
本文提出了一个为基于知识的对话任务自动构建合成训练数据的框架。SynDG首先基于非结构化知识构建对话流,然后通过语言模型将其转化为合成对话,最后过滤并保留生成的高质量对话。实验结果表明,提出的框架在完整的训练数据和低资源场景下都是有效的。进一步的分析表明,随着合成对话数量的增加,模型的性能也趋于提高。对于未来的工作,我们计划研究更有效的策略来确定对话流,并采取更大的语言模型来产生更高质量的合成对话。

