
Arxiv:GPT-4V+多模态情感理解
论文链接:https://arxiv.org/pdf/2312.04293.pdf
代码链接:https://github.com/zeroQiaoba/gpt4v-emotion
论文作者:连政1、孙立才1、孙海洋1、陈康2、温卓凡1、顾浩1、陈顺1、刘斌1、陶建华3
单位:1中国科学院自动化研究所,2北京大学,3清华大学
引言:
GPT-4V具有强大的图文理解能力,已于今年9月份集成到ChatGPT平台中。11月份,OpenAI发布了GPT-4V的API接口,但受限于单日调用100次的限制,难以在基准数据集上进行评测。最近,OpenAI增加了API调用上限到2000次,使得我们能够在基准数据集上直观展示GPT-4V的性能。
多模态情感理解主要涉及四类模态数据:图片、文本、语音和视频。但目前GPT-4V仅支持图片和文本输入。针对视频数据,本文从每个视频中均匀采样三帧作为输入(帧数的影响详见评测论文);对于语音数据,本文试图将语音转成梅尔谱图作为输入,但是GPT-4V拒绝识别梅尔谱图。因此,本次评测主要涉及图片、文本和视频。我们提供了GPT-4V在5类情感理解任务19个数据集上的定量评估结果。代码与评估结果均已开源。
数据集:
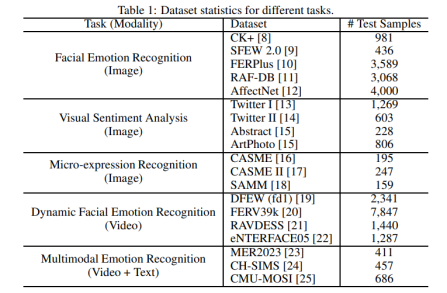
本次评测涉及多模态情感理解中的5类问题:面部表情识别、视觉情感分析、微表情识别、动态面部表情识别、以及多模态情感识别。
评测结果:
本文比较了全监督模型与zero-shot GPT-4V的性能差异。为了降低调用次数,我们采用batch级别输入,即一次输入多个样本同时评测。由于多模态情感理解主要涉及人物,容易触发GPT-4V的拒识规则。我们在prompt设计时要求模型忽略人物身份信息而关注表情,从而降低了拒识次数。
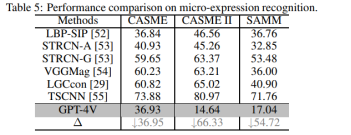
从实验结果中,我们发现在视觉情感分析任务中,GPT-4V甚至能够超越全监督结果;而对于需要专业知识的微表情识别任务,针对通用领域设计的GPT-4V则表现较差。同时,我们进行了消融实验,验证了GPT-4V具有时序理解与多模态理解能力。此外,GPT-4V对于色彩空间的变换也具有一定鲁棒性。具体结果与分析详见评测论文。




我们希望为多模态情感理解任务建立一套zero-shot benchmark,用于后续多模态大模型的评价。此外,我们希望本次评测结果能够对情感计算领域的研究学者有所启发。
引用信息:
Zheng Lian, Licai Sun, Haiyang Sun, Kang Chen, Zhuofan Wen, Hao Gu, Shun Chen, Bin Liu, Jianhua Tao. “GPT-4V with Emotion: A Zero-shot Benchmark for Multimodal Emotion Understanding”. arXiv preprint arXiv:2312.04293 (2023).

连政,助理研究员,2021年于中科院自动化研究所模式识别与智能系统专业获得工学博士学位。2021年7月至今在中科院自动化所工作。研究方向为情感计算。

刘斌,副研究员,硕士生导师。2007年毕业于北京理工大学获得学士学位,2009年毕业于北京理工大学获得硕士学位,2015年于中科院自动化研究所模式识别与智能系统专业获得博士学位。2015年7月至今在中科院自动化所工作。研究方向为情感计算、音频处理等。

陶建华,清华大学长聘教授、博士生导师,国家杰出青年科学基金获得者,国家万人计划科技创新领军人才,享受国务院政府特殊津贴人员。完成多项国家和国际标准,论文和成果曾多次获国内外学术会议奖励。兼任中国计算机学会会士和常务理事、中国人工智能学会常务理事等职务。

