
题目:Multimodal Emotion-Cause Pair Extraction in Conversations
期刊: IEEE Transactions on Affective Computing
作者:汪帆帆,丁子祥,夏睿,李兆宇,虞剑飞
单位:南京理工大学
论文链接:https://ieeexplore.ieee.org/document/9969873
代码链接: https://github.com/NUSTM/MECPE
情绪在人类的沟通和决策中起着重要作用。在文本情绪分析领域,以往的研究主要集中在情绪识别任务上。近年来,情绪原因分析任务受到广泛的关注,其包含两个代表性子任务:1) 情绪原因抽取(Emotion Cause Extraction, ECE),旨在抽取给定情绪的潜在原因;2) 情绪与原因配对抽取(Emotion-Cause Pair Extraction, ECPE),旨在同时抽取情绪及其相应的原因,解决了ECE任务的情绪标注依赖问题。这些研究通常基于新闻、微博或小说文本进行情绪原因分析。
对话是人类交流的重要形式,其中包含了大量的情绪。Poria等人于2021年提出了识别对话文本中情绪原因的任务。然而,对话究其本质是多模态的。视觉、语音等多模态信息对于发现对话中的情绪及其原因尤为重要。例如,我们不仅通过说话人的声音和面部表情来感知其情绪,还要依靠一些视听场景来推测引发说话人情绪的潜在原因。虽然已有很多工作探索了对话中的多模态情绪识别,但据我们所知,目前还缺少对话中多模态情绪原因发现的研究。
本文提出了一个新的任务——对话场景多模态情绪与原因配对抽取(Multimodal Emotion-Cause Pair Extraction, MECPE),目标是在考虑三种模态信息(文本、音频和视频)的情况下,从对话中抽取所有潜在的情绪及其对应的原因。
我们相应构建了一个多模态情绪原因数据集ECF(Emotion-Cause-in-Friends)。ECF数据集以以情景喜剧《老友记》为素材,包含1,374个对话和13,619个话语,标注了9,794个情绪-原因配对。图1展示了ECF数据集中的一个真实样例。在此对话中,我们期望抽取出6个话语级的情绪-原因配对,例如,Chandler在话语4(以下简称U4)中表现的开心情绪是由他和莫妮卡和好这个客观原因和Monica在![]() 中的主观观点触发的,从而构成了(U4, U2)和(U4, U3)两个情绪-原因配对;而U5中Phoebe感到厌恶是因为Monica和Chandler在她面前亲吻这个客观事件(主要体现在U5的视觉模态上),构成了(U5, U5)这个情绪-原因配对。
中的主观观点触发的,从而构成了(U4, U2)和(U4, U3)两个情绪-原因配对;而U5中Phoebe感到厌恶是因为Monica和Chandler在她面前亲吻这个客观事件(主要体现在U5的视觉模态上),构成了(U5, U5)这个情绪-原因配对。
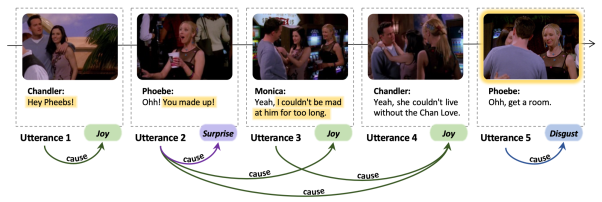
图1 我们标注的ECF数据集样例
我们设计了MECPE任务的两种基线系统:1) 启发式方法,利用原因和情绪相对位置上的内在规律;2) 深度神经网络模型MECPE-2steps,抽取三个模态的特征进行话语表示,分别检测情绪话语和原因话语,最后将情绪话语和原因话语进行配对和过滤。
我们在ECF数据集上评估了基线系统的性能,并与人类表现进行了对比,进一步的实验证明了多模态信息在对话中的情绪和原因分析任务中的潜力。
情绪是一种与思想、感觉和行为反应有关的心理状态。在本文中,它是定义在对话中的每个话语上的一个情绪类别标签,包括Ekman的六类基本情绪(Anger, Disgust, Fear, Joy, Sadness, Surprise)或无情绪(Neutral)。原因是指触发相应情绪的事件或观点。为了便于多模态信息的表示和融合,本文将原因也定义在话语级别。
给定一段由|D|个话语构成的对话(其中每个话语由文本、音频和视频共同表示),我们定义了以下两个任务:
任务1:多模态情绪与原因配对抽取(MECPE),目标是在考虑三种模态的情况下抽取一组情绪原因对
![]()
任务2:考虑情绪类别的多模态情绪与原因配对抽取(MECPE-Cat),其在MECPE的基础上需要进一步为每个情绪-原因配对识别出相应的情绪类别
![]()
以图1中的对话为例,任务1的输出是一组话语级情绪-原因配对:P={(U1,U1), (U2,U2), (U3,U2), (U4,U2), (U4,U3), (U5,U5)}。任务2中的情绪-原因配对包括一个额外的情绪类别,例如(U3,U2,joy)。
情景喜剧中的对话通常比其他电视剧和电影中的包含更多情绪。MELD数据集是标注在情景喜剧《老友记》上的多模态情绪识别数据集。我们在MELD数据集的基础上,进一步标注情绪相应的原因,从而构建了了ECF数据集。
如表1所示,ECF数据集包含涉及三种模态的1,374个对话和13,619个话语,其中标注了7,690个情绪话语和9,794个情绪-原因配对。其中55.73%的话语标注了六种基本情绪之一的情绪类别,91.34%的情绪话语标注了相应的原因。其中一些情绪可能是由涉及多个话语的原因触发的,从而形成了多个情绪-原因配对。另外一小部分情绪并没有标注相应的原因,主要因为这些潜在原因并没有在当前对话中明确表达,而需要通过理解整个对话甚至是整集剧情来推断。
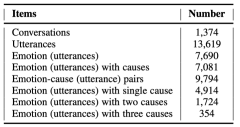
在表2中,我们将ECF数据集与传统情绪原因分析、对话情绪识别和对话情绪原因分析的一些公开数据集进行了模态、场景和规模上的比较。以往的情绪原因分析数据集一般都是基于新闻、微博、小说文本构建的,已有的对话场景下的RECCON数据集也仅考虑了文本模态。目前已有不少用于多模态对话情绪识别任务的数据集,我们则在此基础上进一步标注了原因,构建了规模适中的多模态对话情绪原因分析数据集ECF。
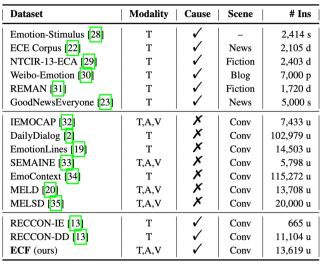
人类行为的原因可能是主观的或者客观的,我们进一步将情绪原因分为两种类型:
客观原因:与真实的外部世界有关的公众可观察到的事物、事件、事实或条件。如图2a和3b所示,客观原因可能体现在文本或视觉场景中。当然,音频中也可能包含一些客观原因,例如说话人因听到了婴儿的哭声而感到惊讶。
主观原因:不能用任何普遍接受的标准证明是对还是错的个人感受、观点、经验或信念。在图2c中,Monica的主观观点让Chandler感到惊讶。而图2d中目标说话人的情绪是由对方的情绪所触发的,这涉及到三种模态。
在ECF数据集中, 71.23%的情绪是由客观原因触发的, 24.48%的情绪是由主观原因触发的, 4.29%的情绪既有客观原因也有主观原因(如图1中U4的情绪)。
我们构建了两种基线系统来对MECPE任务进行基准测试。
启发式方法利用了原因和情绪之间的相对位置规律,即原因一般出现在情绪话语或其之前的几个话语中。我们首先通过训练好的情绪分类器(EPrediction)识别出情绪话语,然后根据在训练集上估计的情绪原因相对位置的两种先验分布(CBernoulli/CMultinomial)对原因话语进行采样。为了测试该方法的上限,我们在第一步中也使用了真实情绪标注(EAnnotation)代替预测情绪,两个步骤的组合就产生了四种启发式方法。
深度神经网络模型MECPE-2steps基于文本模态ECPE任务的代表性方法拓展得到,其结构如图3所示。
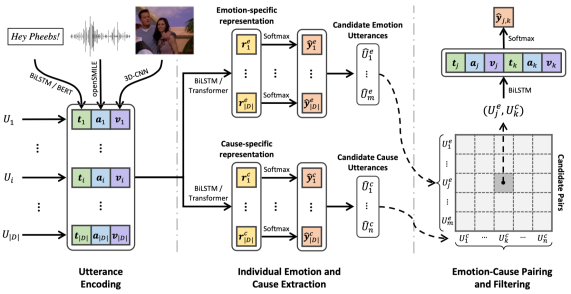
首先分别从话语的三种模态中抽取特征:1) 用GloVe向量初始化文本token,然后送入带有注意力机制的BiLSTM或预训练好的BERT进行编码获得文本特征ti;2) 通过openSMILE工具抽取音频中的声学特征ai;3) 利用一种名为C3D的3D-CNN网络从视频中抽取视觉特征vi。单模态特征拼接起来就得到每个话语的多模态表示,即ui=[ti, ai, vi]。
MECPE-2steps的第一步旨在通过多任务学习抽取一组情绪话语和一组原因话语。我们将独立的话语表示ui输入到两个话语级编码器中,它们的隐藏状态即话语Ui的情绪特定表示rie和原因特定表示ric,分别被输入到两个softmax层中来检测Ui是否为情绪/原因话语。
在获得一组情绪话语和一组原因话语后,我们在第二步中对两个话语集合应用笛卡尔积,得到候选配对集合,然后将情绪话语和原因话语的独立多模态表示以及两个话语之间的距离向量拼接起来表示每个配对,最后通过softmax层来检测候选配对是否为有效的情绪-原因配对。
表3报告了两种基线系统和人类表现在任务1上的实验结果。首先,可以看出,在提供音频或视频后,人类测试者在情绪/原因/配对抽取方面的F1值都有了明显的提高,这说明多模态信息有利于人类更好地理解对话并发现情绪及其相应的原因。其次,启发式方法性能较弱,即使在用真实情绪标注时也是如此,说明MECPE是一项复杂的任务,仅基于相对位置分布的启发式方法不能有效解决问题。深度神经网络模型MECPE-2steps性能显著优于启发式方法。通过融入声学和视觉特征,它可以获得进一步的提升。当使用BERT作为编码器时,它的性能几乎与人类的表现相当,这应该是由于BERT具有很强的表征能力和预训练知识,然而在这种情况下,多模态信息带来的提升较为微弱。
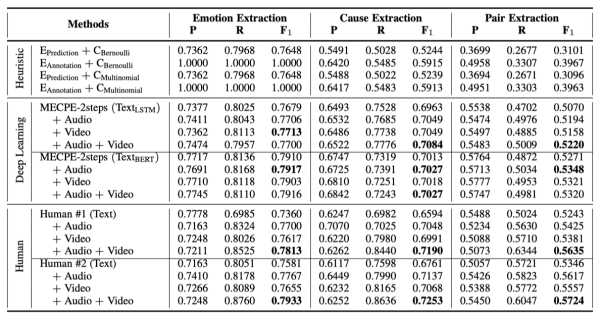
表3 MECPE任务的实验结果
MECPE-Cat任务需要为每个情绪-原因配对进一步预测出情绪类别,各情绪类别下配对抽取的评估结果如表4所示。从表中可以看出,不同情绪类别下的表现随着情绪原因标注比例(如图4所示)的不同而有着显著差异。与MECPE任务的实验结论相似,融入声学和视觉特征后,基线系统的性能显著提高,这表明多模态信息对MECPE-Cat任务也很有帮助。该任务的评估结果相对较低,说明基于MECPE进一步预测情绪类别更具挑战。
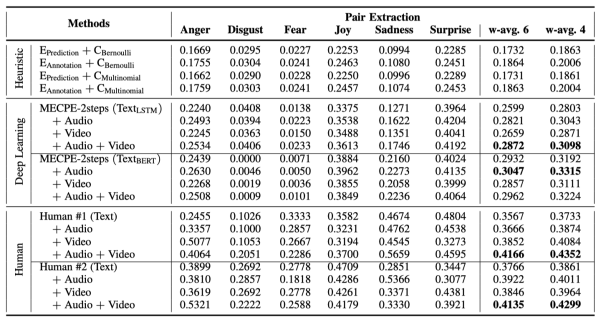
表4 MECPE-Cat任务的实验结果
在这项工作中,我们提出了一个多模态情绪与原因配对抽取(MECPE)的新任务,并相应构建了一个多模态对话情绪原因数据集(ECF)。我们通过建立两种初步的基线系统来对任务进行基准测试,并进行了人类表现测试进行比较。我们还探索了多模态信息对该任务的影响以及融入常识知识的潜力,并考察了在静态和实时两种设置下任务的性能。
对话中的情绪原因分析作为情感计算的一个重要方向,将在智能客服、智能陪伴、心理健康监测等诸多现实应用中发挥重要作用。MECPE任务和ECF数据集的提出,有望为该方向的研究起到促进作用。
MECPE是一项具有挑战性的任务,本文只是对这项任务的初步探索。我们认为以下问题和挑战还值得进一步研究:
如何建立一个多模态对话表示框架,来有效地对齐、交互和融合来自三种模态的信息?
如何有效地建模说话人信息以辅助情绪识别和原因抽取?
如何有效地感知、理解和利用视觉场景来协助对话中的情绪原因推理?
如何利用外部常识知识来发现对话中隐含的情绪和原因?
作者信息:

汪帆帆,南京理工大学计算机科学与技术专业博士生,主要研究方向为对话情感分析。

丁子祥,南京理工大学计算机科学与技术专业博士生。研究方向包括情感分析、信息抽取、社交媒体分析等。在人工智能,自然语言处理等领域国际会议上发表多篇论文。获得第57届计算语言学年会ACL杰出论文奖,并多次担任领域内多个国际会议审稿人。

夏睿,南京理工大学计算机学院教授、博士生导师, 研究方向为自然语言处理、文本情感计算,在领域国际学术期刊和会议发表论文60余篇,出版《文本数据挖掘》、《Text Data Mining》学术专著2部,担任多个国际顶级会议的领域主席、高级程序委员会委员。主持自然科学基金3项、江苏省杰青、优青项目各1项。获得第57届国际计算语言学会年会ACL杰出论文奖、第28届国际计算语言学大会COLING最佳论文候选、教育部自然科学奖二等奖、中国中文信息学会青年创新奖一等奖等奖项。

李兆宇,南京理工大学计算机应用技术专业硕士生,主要研究方向为多模态情感分析。

虞剑飞,南京理工大学计算机学院副教授,硕士生导师。研究方向包括情感分析、信息抽取、社交媒体分析等。在人工智能、自然语言处理等领域国际期刊和会议上发表论文30余篇。获得第28届国际计算语言学大会COLING最佳论文提名。曾担任ACL 2023、ACL Rolling Review的领域主席、ACL 2021的Virtual Infrastructure Co-chair,并多次担任领域内多个国际会议的程序委员会委员和期刊审稿人。
